
Idag finns det tack vare samhällets digitalisering ett överflöd av data att samla in, och det är ingen hemlighet att ledande verksamheter inom en mångfald av branscher tar vara på denna data. Stora mängder data innehåller nämligen ofta information som kan användas till att skapa värde och att tackla problem på ett helt nytt sätt. Tyvärr kan informationen döljas på olika sätt av datans utformning. Ett sådant hinder är när varje datapunkt beskrivs av ett för stort antal parametrar, så kallade dimensioner. Med för många dimensioner blir det svårt för även de mest kraftfulla algoritmerna att producera meningsfulla resultat. För att ändå få ut värdet som finns i datamängden behöver de överflödiga detaljerna skalas bort så att funktionalitet byggs endast på vad som är relevant. Ett sätt att få fram den viktiga delarna är att använda så kallade autoencoders.
En autoencoder är ett speciellt utformat neuralt nätverk som ämnar att lära sig att återskapa datan den tar som input. Detta resulterar alltså i en form av datakomprimering, men autoencoders har även andra spännande tillämpningsområden som t.ex. anomalidetektering och brusreducering som beskrivs längre ner.
En autoencoder består av två delar: en encoder och en decoder. Encoderns uppgift är att komprimera datan samtidigt som så mycket information som möjligt bibehålls. Informationen har reducerats till ett mindre format med så lite informationsförlust som möjligt. Delen av nätverket där den minsta representationen av datan passerar brukar kallas flaskhalsen, som är det sista steget i encodern. Efter flaskhalsen kommer decodern, vilken tar den komprimerade datan och återskapar den till att bli så lik den ursprungliga datan som möjligt. Om decodern lyckas återskapa data som fanns från början visar det att encodern bara skalar bort överflödig information. Encodern kan då användas till att ändra formatet på datan i andra sammanhang.
En av de största fördelarna med autoencoders är att de faller under gruppen Unsupervised learning. Detta innebär att träningsdatan ej behöver vara annoterad. Att annotera data är ofta väldigt dyrt och resurskrävande, så det vill man helst undvika om det inte är absolut nödvändigt.
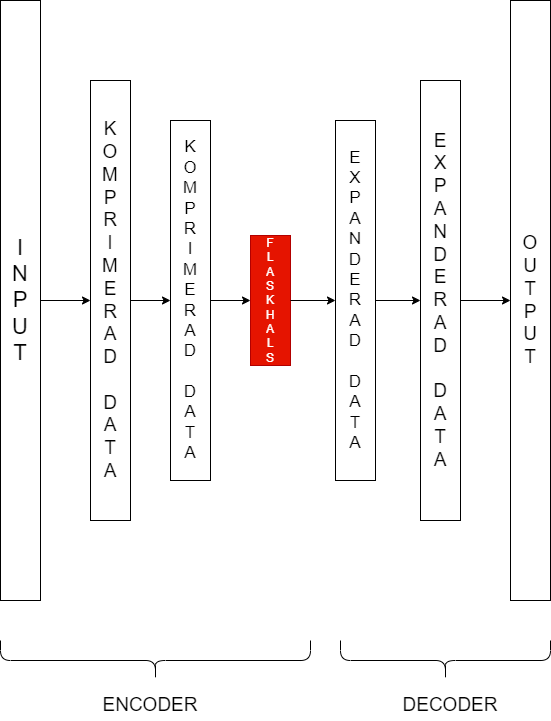
Bilden visar ett diagram för en autoencoder. Inputen går från vänster till höger, och i varje steg fram tills flaskhalsen blir datan mer komprimerad. Decodern speglar sen dimensionerna från flaskhalsen och outputen är lika stor som den ursprungliga inputen.
Nedan kommer tre exempel som demonstrerar hur autoencoders kan användas.
Exempel 1 – Data- och dimensionsreducering
Först visat är exempel på hur autoencoders effektivt kan komprimera data tränades en modell på MNIST-datasetet för handskrivna siffror. Varje bild är 28×28 pixlar, vilket innebär att varje bild totalt har 784 pixelvärden.

Efter att vi kör datan genom vår encoder kommer datan i flaskhals-steget endast bestå av 20 datapunkter. Det är en komprimering av datan med 97.4%! De återskapade bilderna, som tydligt visar samma siffror som originalen, har alltså återskapats från endast 20 datavärden genom decodern.
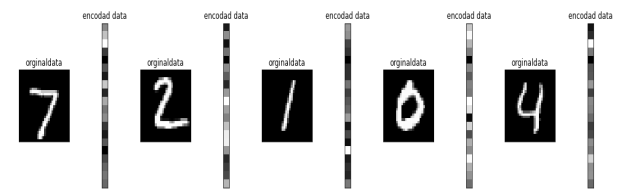
Exempel hur encodern komprimerar orginaldatan från 784 dimensioner ner till en vector med 20 dimensioner.
Det här är den mest typiska användningen av autoencoders. Efter att ha tränat en bra autoencoder kan man t.ex. använda encoderns output som input till ett annat neuralt nätverk för att lösa en uppgift. Detta minska komplexiteten i det efterföljande nätet vilket i många fall leder till bättre resultat.
Ett annat typiskt användningssätt är att utnyttja autoencoders för att komprimera datan som ska transporteras mellan olika system. Då kan avsändaren packa datan med encodern, och mottagaren kan packa upp den med decodern. Tack vare detta minska mängden datan som behöver transporteras avsevärt.
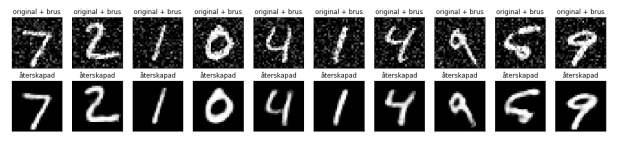
Exempel 2 – Brusreducering
Nästa exempel visar hur autoencoders kan användas för att ta bort brus från datan. Här har inputbilden ett synligt brus, men den återskapade bilden har avlägsnat bruset och endast den relevanta informationen kvarstår. För att få autoencodern lär sig att reducera brus då läggs till brus på inputbilden, och den ursprungliga bilden utan brus används som target variabeln i tränings steget.
Exempel 3 – Anomalidetektion
Det är också möjligt att använda autoencoders för att hitta avvikelser (anomalier) i datan. Genom att jämföra skillnaden i input- och outputdatat kan man identifiera om inputen ligger långt ifrån den önskvärda datan med avseende på träningsdatan. Vad som räknas som “långt ifrån” skiljer sig från problem till problem, och bestäms ofta med ett tröskelvärde man själv kan justera.
I exemplet nedan kan vi se att vår autoencoder, som är tränad för att återskapa handskrivna siffror, inte alls lyckas återskapa bilderna när input istället föreställer kläder. Här är skillnaden mellan input- och outputbilderna väldigt stor och hamnar utanför det satta tröskelvärdet. Dessa bilder kan vi då markera som avvikande, bilderna på kläder innehåller ju inte siffror. Beroende på användningsområde kan man antingen rensa bort dessa eller titta närmare på avvikelserna. Detta kan t.ex.för att identifiera bedrägeri på finansiella marknader, med att identifiera när återskapad transaktion bryter tröskelvärdet på en autoencoder som är tränat med giltiga transaktioner. Om du är intresserad av att använda autoencoders för att upptäcka bedrägeri kan du se mer här.

Sammanfattning
Autoencoders är en speciell typ av neurala nätverk som kan vara kraftfulla verktyg när användaren endast vill behålla nödvändig data, eller när annoterad data är en bristvara. Vi har visat olika användningsområden, bl.a. hur autoencoders kan användas för att avlägsna brus eller hitta anomalier i datan. Utöver de exempel vi tagit upp finns självklart ännu fler användningsområden, som t.e.x bildsegmentering.